Chapter 8 | Approximation Theory¶
Abstract
Target¶
Given \(x_1, \dots, x_m\) and \(y_1, \dots, y_m\) sampled from a funciton \(y = f(x)\), or the continuous function \(f(x)\), \(x \in [a, b]\) itself, find a simpler function \(P(x) \approx f(x)\).
Measurement of Error¶
- (Minimax) minimize
- (discrete) \(E_\infty = \max\limits_{1 \le i \le m}|P(x_i) - y_i|\).
- (continuous) \(E_\infty = \max\limits_{a \le x \le b}|P(x) - f(x)|\).
- (Absolute Deviation) minimize
- (discrete) \(E_1 = \sum\limits_{i = 1}^{m}|P(x_i) - y_i|\).
- (continuous) \(E_1 = \int\nolimits_{a}^{b}|P(x) - f(x)|dx\).
- (Least Squares Method) minimize
- (discrete) \(E_2 = \sum\limits_{i = 1}^{m}|P(x_i) - y_i|^2\).
- (continuous) \(E_2 = \int\nolimits_{a}^{b}|P(x) - f(x)|^2dx\).
In this course, we only discuss the minimax and least square parts, and only make \(P(x)\) a polynomial function.
General Least Squares Approximation¶
Definition 8.0
\(w\) is called a weight function if
-
(discrete)
\[ \forall\ i \in \mathbb{N},\ \ w_i > 0. \] -
(continuous) \(w\) is an integrable function and on the interval \(I\),
\[ \forall\ x \in I,\ \ w(x) \ge 0, \]\[ \forall\ I' \subseteq I,\ \ w(x) \not\equiv 0. \]
Considering the weight function, the least square method can be more general as below.
- (discrete) \(E_2 = \sum\limits_{i = 1}^{m}w_i|P(x_i) - y_i|^2\).
- (continuous) \(E_2 = \int\nolimits_{a}^{b}w(x)|P(x) - f(x)|^2dx\).
Discrete Least Squares Approximation¶
Target¶
Approximate a set of data \(\{(x_i, y_i) | i = 1, 2, \dots, m\}\), with an algebraic polynomial
of degree \(n < m - 1\) (in most case \(n \ll m\)), with the least squares measurement, w.r.t. and weight function \(w_i \equiv 1\).
Solution¶
The necessary condition to minimize \(E_2\) is
Then we get the \(n + 1\) normal equations with \(n + 1\) unknown \(a_j\),
Let \(b_k = \sum\limits_{i = 1}^m x_i^k\) and \(c_k = \sum\limits_{i = 1}^m y_i x_i^k\), we can represent the normal equations by
Theorem 8.0
Normal equations have a unique solution if \(x_i\) are distinct.
Proof
Suppose \(X\) is an \(n + 1 \times m\) Vandermonde Matrix, which is
and let \(\mathbf{y} = (y_1, y_1, \cdots, y_m)^T\).
Then the normal equations can be represented by (notice the dimension of matrices and vectors),
Since \(x_i\) are distinct, \(X\) is a column full rank matrix, namely
Since \(x_i \in \mathbb{R}\), thus
Hence the normal equations have a unique solution.
Logarithmic Linear Least Squares¶
To approximate by the function of the form
or
we can consider the logarithm of the equation by
and
Note
It's a simple algrebric transformation. But we should point out that it minimize the logarithmic linear least squares, but not linear least squares.
Just consider the arguments to minimize the following two errors,
and
they are slightly different actually.
Continuous Least Squares Approximation¶
Now we consider the continuous function instead of discrete points.
Target¶
Approxiate function \(f \in C[a, b]\), with an algebraic polynomial
with the least squares measurement, w.r.t the weight function \(w(x) \equiv 1\).
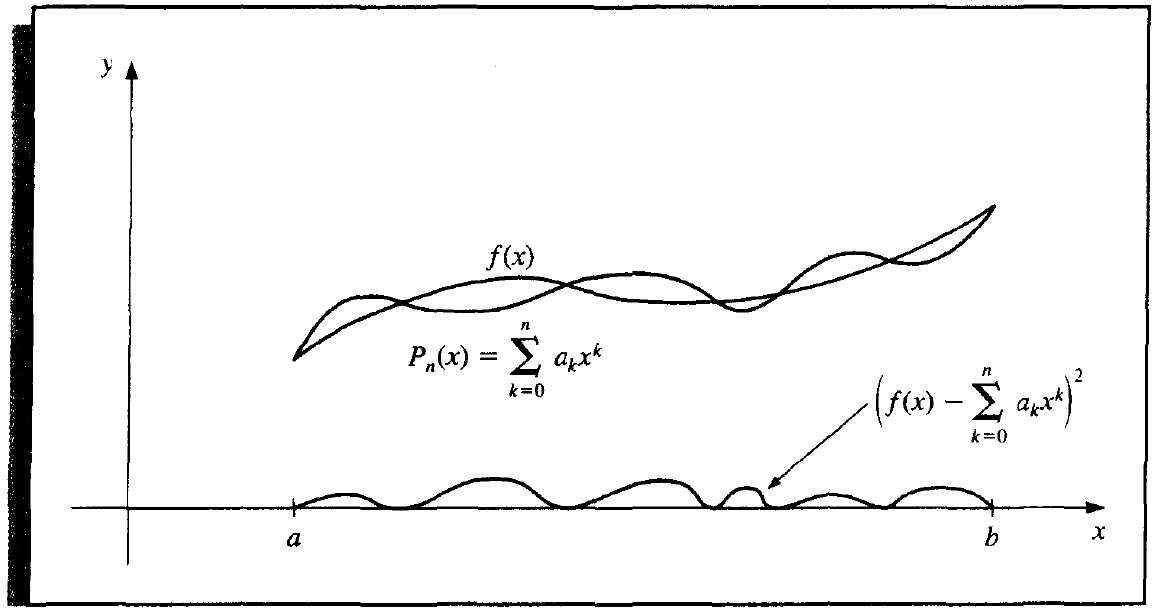
Solution¶
Problem
Similarly to the discrete situation, we can derive the normal equations by making
and we get the normal equations
However, notice that
Thus the coefficient of the linear system is a Hilbert matrix, which has a large conditional number. In actual numerical calculation, this gives a large roundoff error.
Another disadvantage is that we can not easily get \(P_{n + 1}(x)\) from \(P_{n}(x)\), similarly with the discussion of Lagrange interpolation.
Hence we introduce a different solution based on the concept of orthogonal polynomials.
Definition 8.1
The set of function \(\{\varphi_0(x), \dots, \varphi_n(x)\}\) is linearly independent on \([a, b]\) if, whenever
we have \(c_0 = c_1 = \cdots = c_n = 0\). Otherwise it's linearly dependent.
Theorem 8.1
If \(\text{deg}(\varphi_j(x)) = j\), then \(\{\varphi_0(x), \dots, \varphi_n(x)\}\) is linearly independent on any interval \([a, b]\).
Theorem 8.2
\(\Pi_n\) is the linear space spanned by \(\{\varphi_0(x), \dots, \varphi_n(x)\}\), where \(\{\varphi_0(x), \dots, \varphi_n(x)\}\) is linear independent, and \(\Pi_n\) is the set of all polynomials of degree at most n.
Definition 8.2
For the linear independent set \(\{\varphi_0(x), \dots, \varphi_n(x)\}\), \(\forall P(x) \in \Pi_n\), \(P(x) = \sum\limits_{j = 0}^n \alpha_j \varphi_j(x)\) is called a generalized polynomial.
Definition 8.3
Inner product w.r.t the weight function \(w\) is defined and denoted by
- (discrete) \((f, g) = \sum\limits_{i = 1}^{m} w_i f(x_i)g(x_i)\)
- (continuous) \((f, g) = \int\nolimits_{a}^{b} w(x) f(x) g(x) dx\).
\(\{\varphi_0(x), \dots, \varphi_n(x)\}\) is an orthogonal set of functions for the interval \([a,b]\) w.r.t the weight function \(w\) if
In addition, if \(\alpha_k = 1\), then the set is orthonormal (单位正交).
Motivation of Orthogonality
Considering \(w(x)\), then the normal equations can be represented by
If we define the orthogonal set of functions as above, the equations reduce to
Theorem 8.3
\(\{\varphi_0(x), \dots, \varphi_n(x)\}\) is an orthogonal set of functions on the interval \([a, b]\) w.r.t. the weight function \(w\), then the least squares approximation to \(f\) on \([a, b]\) w.r.t. \(w\) is
where, for each \(k = 0, 1, \dots, n\),
Base on the Gram-Schmidt Process, we have the following theorem to construct the orthogonal polynomials on \([a, b]\) w.r.t a weight function \(w\).
Theorem 8.4
The set of polynomial functions \(\{\varphi_0(x), \dots, \varphi_n(x)\}\) defined in the following way is orthogonal on \([a, b]\) w.r.t. the weight function \(w\).
where
Minimax Approximation¶
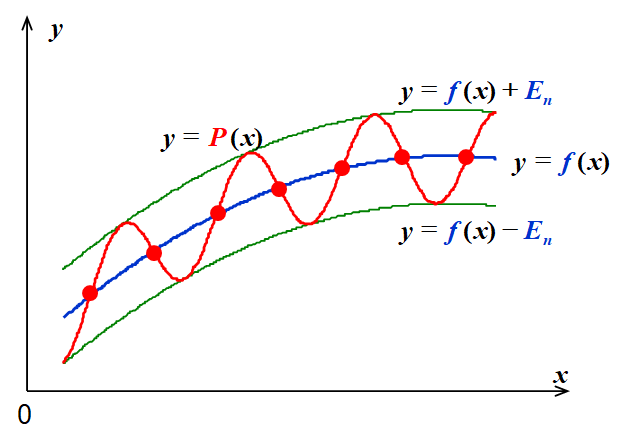
The minimax approximation to minimize \(||P - f||_\infty||\) has the following properties.
Proposition
- If \(f \in C[a, b]\) and \(f\) is not a polynomial of degree \(n\), then there exists a unique polynomial \(P(x)\) s.t. \(||P - f||\infty\) is minimized.
- \(P(x)\) exists and must have both \(+\) and \(-\) deviation points.
-
(Chebyshev Theorem) The \(n\) degree \(P(x)\) minimizes \(||P - f||_\infty\) \(\Leftrightarrow\) \(P(x)\) has at least \(n + 2\) alternating \(+\) and \(-\) deviation points w.r.t. \(f\). That is, there is a set of points \(a \le t_1 < \dots < t_{n + 2} \le b\) (called the Chebyshev alternating sequence) s.t.
\[ P(t_k) - f(t_k) = (-1)^k||P - f||_\infty. \]
Here we introduce Chebyshev polynomials to deal with \(E_\infty\) error, and by the way, we can use it to economize the power series.
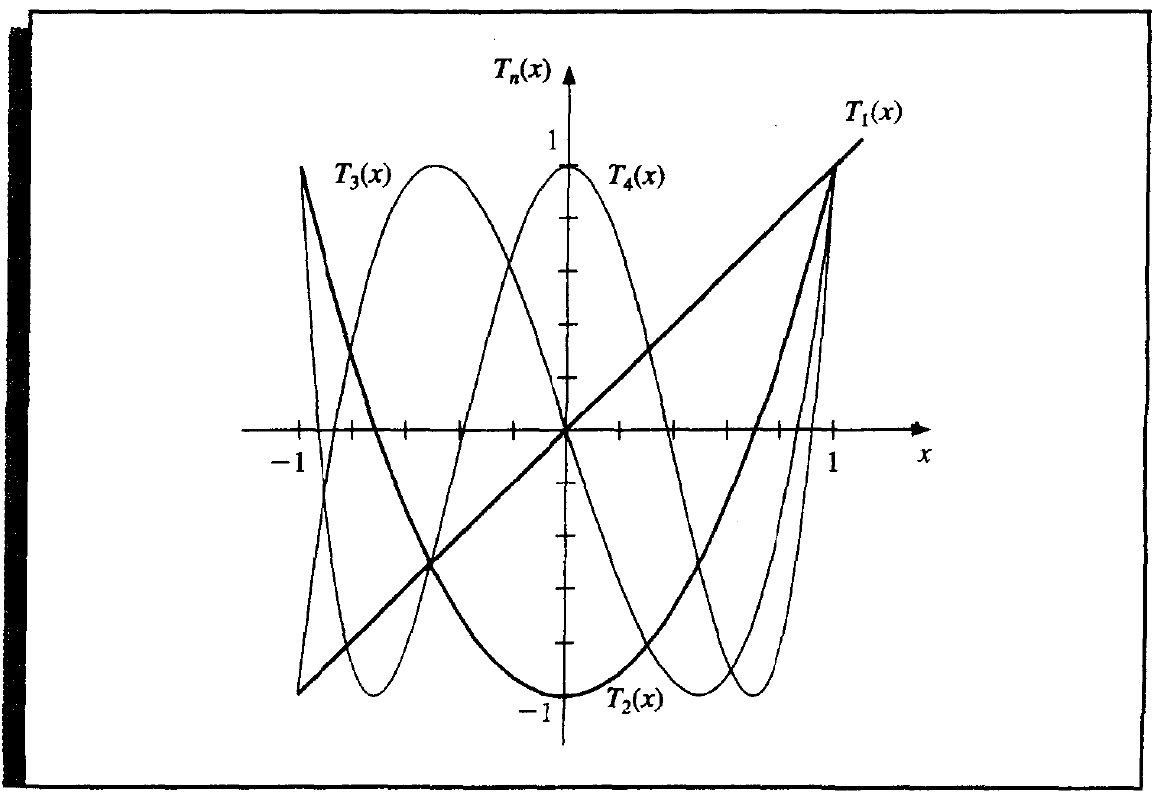
Chebyshev Polynomials¶
Chebyshev polynomials are defined concisely by
or equally defined recursively by
Property
-
\(\{T_n(x)\}\) are orthogonal on \((-1, 1)\) w.r.t the weight function
\[ w(x) = \frac{1}{\sqrt{1 - x^2}}. \]\[ (T_n, T_m) = \int_{-1}^1 \frac{T_n(x)T_m(x)}{\sqrt{1 - x^2}}dx = \left\{ \begin{aligned} & 0, && n \ne m, \\ & \pi, && n = m = 0, \\ & \frac{\pi}{2}, && n = m \ne 0. \end{aligned} \right. \] -
\(T_n(x)\) is a polynomial of degree \(n\) with the leading coefficient \(2^{n - 1}\).
-
\(T_n(x)\) has \(n\) zero points at
\[ \bar{x}_k = \cos \left(\frac{2k-1}{2n}\pi\right),\ k = 1, 2, \dots, n. \] -
\(T_n(x)\) has extrema at
\[ \bar{x}'_k = \cos \frac{k\pi}n \text{, with } T(\bar{x}'_k) = (-1)^k,\ k = 1, 2, \dots, n. \]
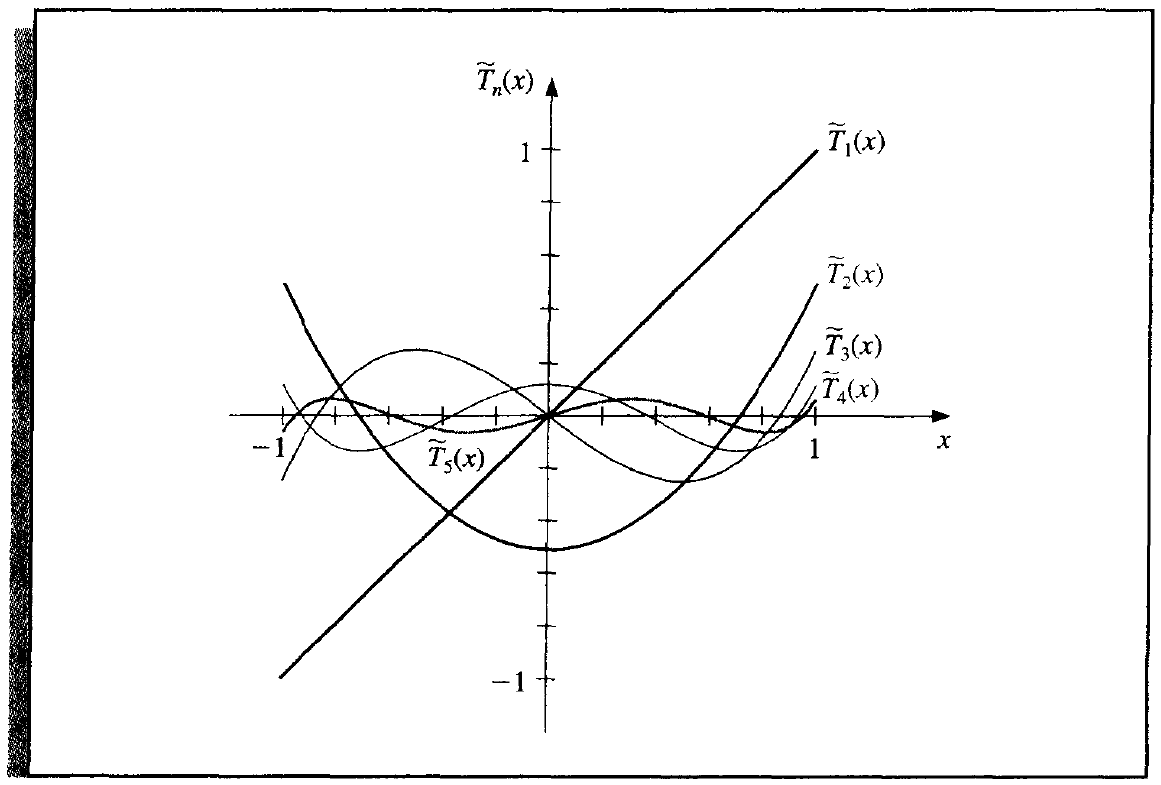
Monic Chebyshev Polynomials¶
Monic chebyshev polynomials are defined by
The following is an important theorem for the position of Chebyshev polynomials.
Theorem 8.5
where \(\tilde \Pi_n\) denotes the set of all monic polynomials of degree n.
From theorem 8.5, we can answer where to place interpolating points to minimize the error in Lagrange interpolation. Recap that
To minimize \(R(x)\), since there is no control over \(\xi\), so we only need to minimize
Since \(w_n(x)\) is a monic polynomial of degree \((n + 1)\), we can obtain minimum when \(w_n(x) = \tilde T_{n + 1}(x)\).
To make it equal, we can simply make their zero points equal, namely
Corollary 8.6
Solution of Minimax Approximation¶
Now we come back to the minimax approximation. To minimize
with a polynomial of degree \(n\) on the interval \([a, b]\), we need the following steps.
Step.1 Find the roots of \(T_{n + 1}(t)\) on the interval \([-1, 1]\), denoted by \(t_0, \dots, t_n\).
Step.2 Extend it to the interval \([a, b]\) by
Step.3 Substitue \(x_i\) into \(f(x)\) to get \(y_i\).
Step.4 Compute the Langrange polynomial \(P(x)\) of the interpolating points \((x_i, y_i)\).
Ecomomization of Power Series¶
Chebyshev polynomials can also be used to reduce the degree of an approximating polynomials with a minimal loss of accuracy.
Consider approximating
on [-1, 1].
Then the target is to minimize
Solution¶
Since \(\frac{1}{a_n}(P_n(x) - P_{n - 1}(x))\) is monic, thus
Equality occurs when
Thus we can choose
with the minimum error value of
创建日期: 2022.11.10 01:04:43 CST